SEITSEMÄN AI-KORTTIA Koneäly on tulossa voimalla sulautettuihin tietojärjestelmiin. Siksi kokosimme tähän perustiedot tekoälylaskennasta, mutta esittelemme myös seitsemän pienkorttia. Niiden avulla voit kokeilla helposti tekoälytekniikan sovittamista sulautettuihin ratkaisuihin.
Teksti Tomi Engdahl ja aloituskuva Nvidia
Tekoäly nähdään entistä useammin tärkeäksi osaksi tulevaisuuden esineiden internetin ja esimerkiksi robottien ja autonomisten ajoneuvojen kehittämistä. Myös tarve prosessoida dataa yhä enemmän siellä missä data syntyy, on viemässä koneoppimista ja tekoälyä yhä pienempiin laitteisiin.
Tekoälystä koneoppimiseen
Tekoäly ei ole vain yksi teknologia, vaan nimikkeen alle kuuluu laaja joukko erilaisia menetelmiä, teknologioita, sovelluksia ja tutkimussuuntia. Tekoäly on muutenkin käsitteenä paljon odotettua laajempi ja moniulotteisempi. Tekoälylle löytyy monia eri määritelmiä, mutta lähtökohtaisesti kaikissa niissä tekoälyn ilmoitetaan olevan tietokoneen ja ohjelmiston kyvyksi reagoida ihmisälyn kaltaisesti erilaisiin tilanteisiin.
Yhä useampi uudempi sovellus hyödyntää jo jonkinlaista tekoälyä, jossa koneoppiminen (machine learning) on keskeisessä osassa. Siinä etsitään tapoja muuttaa automaattisesti tietoa muodosta toiseen. Tyypillisiä sovelluksia koneoppimiselle ovat kuvan ja puheentunnistus, joita voidaan käyttää niin valvontakameroiden kuin robottiautojen kanssa. Yleisin sovellus taitaa olla kuitenkin puheentunnistus esimerkiksi Applen älypuhelimien Siri- tai Amazonin älykaiutintoteutuksissa.
Neuroverkoilla syvempää oppimista
Koneoppimisen parhaimpana tasona pidetään syvän oppimisen (DL) järjestelmiä. Ne ovat käytännössä informaation käsittelyn, matematiikan tai laskennan malleja, jotka perustuvat yhdistävään laskentaan. Hermoverkkojen perusteorialla on ikää vuosikymmeniä, mutta viime vuosina algoritmien optimoinnit ja tietotekniikan laskentatehon kasvaminen ovat tehneet tekniikasta käytännössä laajasti sovellettavaa.
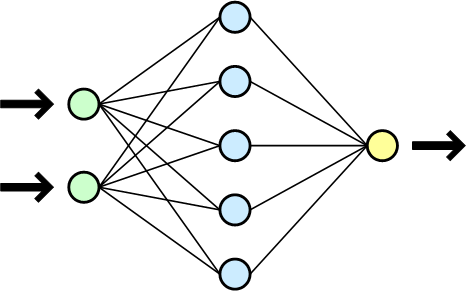
Example of a 2×5 multilayer neural network. Colored spheres depict neurons and the lines between them are the connections between them.
Syväppimisjärjestelmät perustuvat moniin algoritmeihin, mukaan lukien syvähermoverkko (DNN), konvoluutiohermosverkot (CNN), toistuvat hermoverkot (RNN) ja monet muut variaatiot.
Algoritmeja on tarjolla eri tehtäviin. Esimerkiksi konvoluutiohermosverkot (convolutional neural networks, CNN) soveltuvat parhaiten tuottamaan liikkuvaa tilannekuvaa sulautetun auton näkötekniikan toteuttamiseen. Toistuvilla hermoverkoilla (recurrent neural networks, RNN) voidaan puolestaan selvittää, esimerkiksi onko kuvassa oleva kohde koira vai henkilö tai mihin se on siirtymässä.
Jokaisella eri lähestymistavoista on aina kompromisseja eri ominaisuuksien suhteen, ja vaatii asiantuntemusta, että kokeilua valita sopivin algoritmi kuhunkin käyttötarkoitukseen.
Kaikki edellä esitetyt algoritmityypitkin ovat vain eri variaatioita samasta perusteemasta: useita neutroneita sisältäviä solmukerroksia, viestintää solmujen välillä ja viestintää solmukerrosten välillä. Neuroverkkojen perusajatus perustuu karkeasti ihmisaivojen luonnollisiin hermoverkkojen sekä ihmisaivojen tapaan oppia jäljittelemiseen.
Työkaluja tekoälyn luomiseen
Koneoppimisen toteuttamiseen on saatavissa jo monia ohjelmistokirjastoja. Niistä Googlen julkaisema TensorFlow on yksi suosituimmista. Se on kirjoitettu Python-kielellä, mutta siitä on olemassa myös selaimessa pyörivä JavaScript-versio tensorflow.js. Muita suosittuja laajasti tuettuja koneoppimiskirjastoja ovat muun muassa PyTorch, Caffe ja Scikit-learn. Listasimme artikkelin linkkipankkiosioon yhteydet kaikkiin näihin kirjastotuotteisiin.
Usein ajatellaan, että syväneuroverkon opettaminen ja suorittaminen vaativat aina palvelinfarmeittain laskentatehoa, mutta tilanne on ainakin sulautetuissa sovelluksissa hiljalleen muuttumassa. Aiemmin sulautettu laitteisto nähtiin jopa liian keveinä kyetäkseen ajamaan syväneuroverkkojen (DNN, deep neural network) -algoritmeja, mutta nyt tarjolle on tullut näihin sovelluksiin optimoituja laitteistoja. Samalla on kehitetty uusia simppelimpiä neuroverkkolaskentamalleja. Ja kun neuroverkkomalli on kerran opetettu, tällaista opetettua neuroverkkomallia voidaan hyödyntää helposti.
Valmiin neuroverkkomallin käyttäminen (esimerkiksi kuvan luokittelu) vaatii selvästi vähemmän suoritintehoa, kun kokonaan uuden mallin opettaminen. Yksi tapa keventää laskentaa on korvata liukulukulaskentaa kiinteän pisteen esityksellä tai optimoida mallista pois tarpeettomia osia. Tai kolmas tapa on pienentää syöttödatan määrää (esimerkiksi kuvan resoluutiota) niin, että sitä voidaan käsitellä pienemmällä neuroverkolla ja vähemmällä laskennalla.
Kaikkien näiden toimien avulla voidaan sulautetuissa ratkaisuissa vähentää muistin ja virran tarvetta säilyttäen samalla kyseiseen tarpeeseen riittävä tarkkuus. Kannattaakin miettiä sovelluksen datanhallintaa kokonaisuutena. Suuret tietomäärät kannattaa käsitellä yleensä lähellä sen tuotantopaikkaa, koska voit hukata helposti paljon tehoa tiedon siirtoon.
Suurien tietomäärien käsittelyssä myös pakkaus, kvantisointi, karsinta, ryhmittely, prosessorin tietojen uudelleenlatauksen minimointi ovat ehdottoman tärkeitä. Ja jos sulautettu laite ei pysty tekemään kaikkea itse, yksi vaihtoehto on käyttää suhteelisen simppelia tekoälyalgoritmia etsimään syötedatasta poikkeavuuksia, joita voidaan sitten analysoida tarkemmin verkon pilvipalvelussa.
Laitteisto ja ohjelmisto yhteen

Tekoälyn (AI) ja erityisesti syvän oppimisen (DL) toteuttaminen vaati yleensä tehokkaasti siihen tehtävään varten optimoitua laitteistoja ja ohjelmistoa. Toki perinteisellä prosessorillakin voi laskentaa tehdä, mutta se ei ole erityisen nopeaa tai energiatehokasta. Tarvetta on erikoisprosessorille tai ainakin kortille, jossa on mukana laskentaa vauhdittavaa tekniikkaa.
Silti alkuvaiheessa helpoin on lähteä liikkeelle ohjelmistopohjaisena ja yleisprosessorilla. Ratkaisussa tarvitaan vain sopiva AI-ohjelmisto, joka on tyypillisesti toteutettu Python tai C++ kielellä. Toki ratkaisulla ei voi toteuttaa kovinkaan monimutkaista sovellusta tai pian törmätään normaalilaitteiston suorituskyvyn rajoitteisiin.
Siksi oikeat tekoälylaskentaan paremmin sopivat arkkitehtuurimenetelmät ovat tarpeen. Ne toteuttavat paljon enemmän operaatioita sekunnissa ja wattia kohti kuin mitä perinteiset tavat kykenevät saavuttamaan. Esimerkiksi kuvan ja äänen käsittelyyn suunnitellut signaaliprosessorit sopivat syvän tekoälyoppimisen sovelluksiin.
Myös tietokonegrafiikan tuottamiseen erikoistuneet grafiikkasuorittimet (Graphics Processing Unit, GPU) soveltuvat tekoälylaskentaan, josta kertoo myös grafiikkapiirivalmistaja NVIDIA:n kiinnostus tekoälysovellusten laiteratkaisuihin. Niiden rinnakkaislaskentaan sopiva rakenne ja huippunopea muistiväylä nopeuttavat monimutkaistenkin algoritmien laskemista.
Grafiikkapiirien GPU-laskenta on ollut jo pitkään laajasti käytetty tekniikka koneoppimisen tehostamisessa, datakeskuksissa ja päätelaitteissa. Niiden tärkeimmät ohjelmointirajapinnat ovat CUDA sekä OpenCL. Myös ohjelmoitavilla FPGA-piireillä voi toteuttaa hyvin pitkälle rinnakkaisesti toimiva tehokas laskentayksikkö tai piirin logiikka voidaan ohjelmoida jopa mallintamaan hermoverkon rakennetta. Niillä voidaan toteuttaa optimoitu laskentalaitteisto, jonka ominaisuuksia voi tarvittaessa muuttaa. FPGA-piirejä voidaan hyödyntää kaikissa ML-sovelluksissa palvelinkeskussovelluksista aina pienitehoisiin antureihin.
Lisäksi asiakaskohtaisilla ASIC-piireillä on mahdollista tuottaa tekoälyratkaisuun optimoituja piirejä. Ongelma on, ettei ASIC-piiriä ole yhtä helppo muuttaa kuin ohjelmoitavia FPGA-piirejä. Siksi niihin on usein integroitu myös syväoppimislaskentaan sopivia prosessoriytimiä, joiden toimintaa voidaan puolestaan ohjata ohjelmoimalla.
Yhä edelleen monet tekoälyalustoiksi markkinoiduista korttitietokoneista ovat monelta osin normikortteja, jotka koostuvat yleiskäyttöisestä keskusyksiköstä, muistista, tehonhallinasta sekä yhdestä tai useammasta neuroverkkolaskentaan sopivasta laskentakiihdyttimestä.
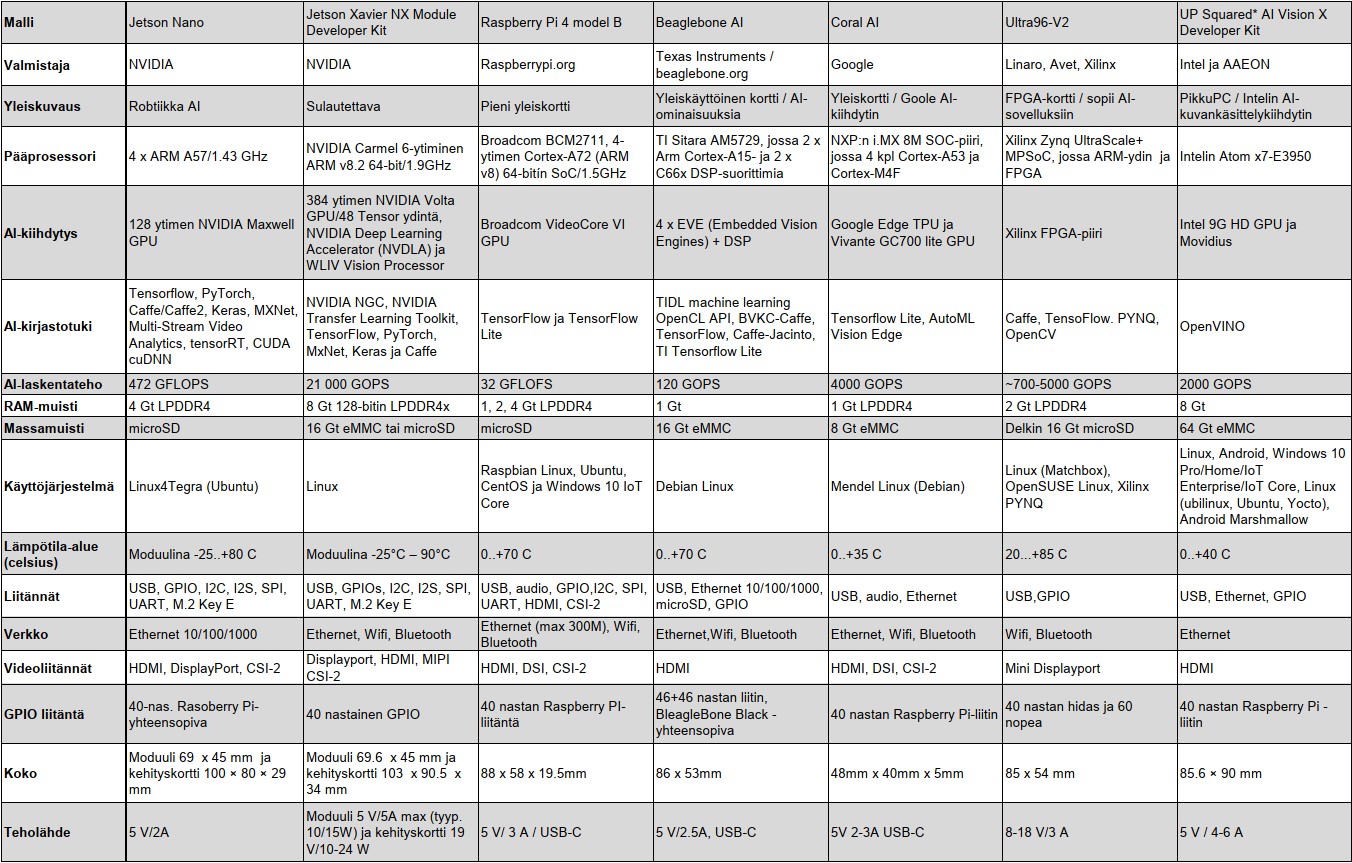
Korteilla olevat laskentakiihdyttimet voivat rakentua ohjelmoitavasta grafiikkasuorittimesta, DSP-lohkosta, FPGA-piiristä tai neuraalilaskentaa varten kehitetystä apuprosessorimoduulista. Myös valmiita tekoälylaskentaan sopivia tehoyksiköitä on tarjolla. Tässä on esillä seitsemän AI-suoritinkorttia, joiden avulla voidaan kokeilla tekoälylaskennan toteuttamista.
Raspberry Pi 4 sopii myös koneälyyn

Raspberry Pi Foundationin harrastajille alkuaan kehittämä korttitietokone on löytänyt tiensä myös tekoälyratkaisuihin uusimman Pi 4 -version lisätehon ansiosta. Sillä voidaan ajaa TensorFlow-hermoverkkomalleja tai esimerkiksi MobileNet-kuvantunnistusta.
Raspberry Pi 4:ssa on Broadcom BCM2711-järjestelmäpiiri, johon on integroitu neliytiminen 1,5 gigahertsin kellotaajuudella toimiva Cortex-A72 (ARM v8) suoritin ja VideoCore VI GPU-grafiikkasuoritin.
Kortilla on myös Bluetooth Low Energy 5.0 -piiri, gigabitin Ethernet- ja kaksi USB 3.0-liitäntää sekä kaksi mikro-HDMI-videolähtöä.
Korttia on tarjolla joko yhden, kahden ja neljän gigatavun LPDDR4-2400 SDRAM-muistilla. Massamuistina on microSD-kortti. Laajennuksia varten kortilla on 40-nastainen GPIO-laajennusliitin.
Jetson Nano tuo laskentatehoa
Grafiikkakorttivalmistaja NVIDIA:n Jetson Nano on pieni korttitietokone, jonka avulla voit toteuttaa erilaisia hermoverkkoratkaisuja. Siitä on pyritty tekemään varsin edullinen vähän tehoa kuluttava versio valmistajan Tegra X1 – ammattiversioista. Se sopii valmistajan mukaan esimerkiksi kuvien luokitteluun, kohteiden havaitsemiseen, segmentointiin tai puheenkäsittelyyn. Valmistaja on demonnut korttia myös robotiikan konenäkösovelluksiin.

Jetson Nano -kortti tarjoaa pääprosessorin (4x A57 @ 1,43 GHz) ja normaalia suurempaa laskentakapasiteettia tarjoavan GPU-yksikön (128 ydintä Maxwell-sukupolven @ 921 MHz). Kortilla on neljä gigatavua LPDDR4-muistia. Kortissa on myös Raspberry Pi lisäkorttien kanssa yhteensopiva 40-nastainen GPIO-liitin.
Kortin käyttöönotto on pyritty tekemään mahdollisimman helpoksi. Käyttäjän tarvitsee vain asettaa järjestelmäkuvan sisältävä microSD-kortti paikalleen ja käynnistää kortti toimintaan. NVIDIA tarjoaa sitä myös reunalaskentatuotteisiin suunnatun moduuliversion.
Kehitysympäristönä on tarjolla yrityksen oma JetPack SDK, jota käytetään myös muissa aiemmin julkistetuisa Jetson-tuoteperheen tuotteissa. Käyttöjärjestelmä on Linux4Tegra, joka pohjautuu Ubuntu Linuxiin.
Uusin Jetsonin NX myös paketissa
NVIDIAn uusi tuote on SOM-moduulimuodon Jetson Xavier NX, joka on tarkoitettu reunalaskentaa ja ajoneuvosovelluksia varten. Moduuli pystyy tarjoamaan jopa 21 biljoonaa operaatiota sekunnissa (TOPS) laskentanopeuden 8 bitin tarkkuudella suoritettavalle AI-laskennalle.
Jetson Xavier NX -moduulin tarjoaa yli kymmenkertaisen suorituskyvyn verrattuna sen laajalti hyväksyttyyn edeltäjään Jetson TX2:een. Verrattuna Jetson Nano-korttiin, Jetson Xavier NX tarjoaa moninkertaisti AI-laskentakykyä noin nelinkertaiseen hintaan.
Xavier NX perustuu järjestelmäsirupakkaukseen, joka sisältää kuusi NVIDIA Carmel ARMv8.2-prosesori ydintä, Volta-pohjaisen GPU-grafiikkaprosessointiyksikön, NVIDIA: n Deep Learning Accelerator (NVDLA) yksiköitä sekä WLIV Vision Processor -kuvankäsittelyprosessoreja.

GPU-yksikkö tarjoaa 384 CUDA-ydintä ja 48 Tensor-ydintä. Järjestelmämoduuli on suunniteltu toimimaan 5V käyttöjännitteellä, ja se pysty tarjoamaan 21 TOPS suorituskyvyn 15W tehonkulutuksella. Tarvittaessa moduulin tehoprofiilia voidaan säätää. Esimerkiksi valmis 10W-tehonkulutusprofiilii tarjoaa 14 TOPS laskentatehon.
Jetson Xavier NX Module Developer Kit sisältää järjestelmämoduulin, sille sopivan emokortin, tuulettimella varustetun jäähdytysrivan sekä teholähteen. Kortti toimii 19 voltin jännitteellä, kuten monet kannettavat tietokoneet ja tehonkulutus on 24 wattia.
NX-kehityskortti tarjoaa liitäntöinä neljä USB 3.1- ja yhden USB 2.0 Micro-B -porttin, gigabitin Ethernet-portin, HDMI- tai DisplayPort-näyttöliitännän, kaksi MIPI CSI-2 -kameraliitäntää, microSD-korttipaikan, 40-nastaisen GPIO-laajennusportin sekä M.2 Key E -korttipaikan, johon asennettu tietoliikennekortti tarjoaa langattomat WiFi- ja Bluetooth-liitännät.
Kortin käyttöjärjestelmänä on Linux ja se tukee NVIDIA:n Cloud Native -infrastruktuuria. Kortin sovelluksia kehitetään apuna käyttäen pilvipohjaisia työkaluja, jonka avulla voidaan määrittää, millaisia konttimuodossa jaettavia reunalaitteessa tullaan suorittamaan.
Kortti tukee monia AI-kirjastoja, ja Jetson Nano kortille tehdyt mallit on siirrettävissä toiminaan Jetson Xavier NX ympäristössä. NVIDIA tarjoaa tälle kortille esikoulutettuja AI-malleja NVIDIA NGC ja NVIDIA Transfer Learning Toolkit -sovelluskirjastoissaan.
Texas Instrumentsin Beaglebone AI
Piirivalmistaja Texas Instrumentsin Beaglebone on brittiläisen Raspberry Pin ohella varsin suosittu pienen korttikoon tuote. Nyt siitä on tekoälysovelluksiin tarjolla oma BeagleBone AI-versio, joka pohjaa BeagleBoard.orgin avoimen lähdekoodin Linux-rakenteisiin.
BeagleBone AI-korttialusta on suunniteltu ensimmäisiin kokeiluihin, kun halutaan tutkia, miten tekoälyä (AI) voitaisiin käyttää hyödyksi eri aloilla. Kortti on suunni
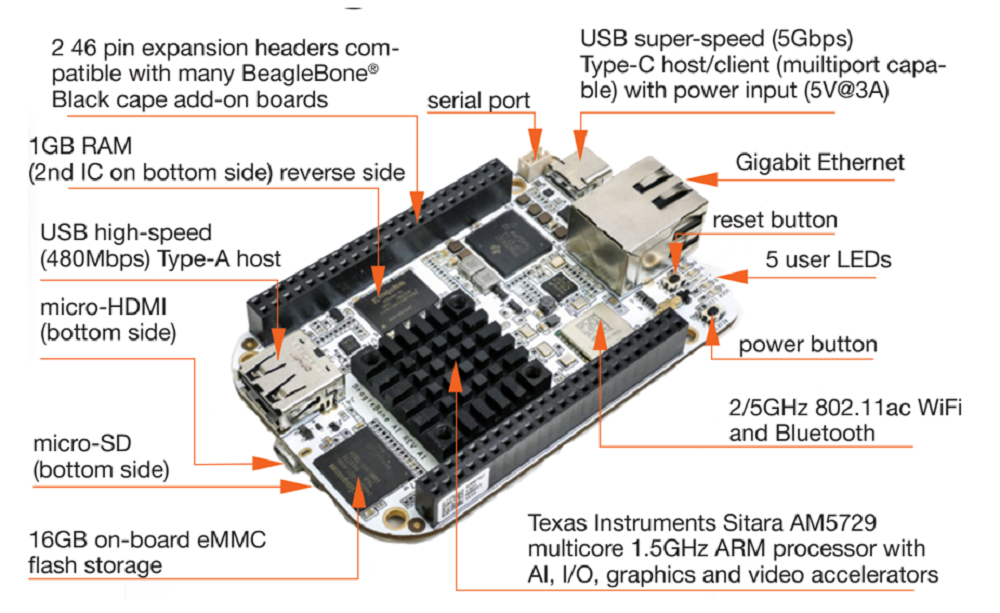
teltu täyttämään aukkoa pienten korttitietokoneiden ja tehokkaampien teollisuustietokoneiden välillä. Kortin avulla
Koneoppimisprosessointia varten kortissa on kahden ARM:n A15-prosessoytimien lisäksi kaksi signaaliprosessoriydintä (TI C66x) sekä neljä kuvansignaalien käsittelyyn optimoitua EVE (Embedded Vision Engines) -laskentayksikköä.
Laskentayksiköiden käyttöä tuetaan laajoilla ohjelmakirjastoilla, jotka tukevat muun muassa TI Deeplearning Lib (TIDL), OpenCL API, BVKC-Caffe ja TensorFlow.
BeagleBone AI on liitäntöjen ja mekaanisten mittojen osalta yhteensopiva valmistajan aikaisemman BeagleBone Black -kortin kanssa. Siitä tukee edelleen myös aiempi kehityspaketti BeagleBone AI AM5729 development board for embedded Artificial Intelligence.
Verkkojätti Googlen pieni Coral AI
Googlen Coral AI Dev Board on varsin pieni yhden kortin tietokone, jossa on NXP:n i.MX 8M SOC (4 x Cortex-A53 + Cortex-M4F) pääprosessori sekä neuroverkkolaskentaa varten Googlen TPU Edge-piiri. Järjestelmämoduuli (SOM) sisältää eMMC-massamuistin, järjestelmäpiirin, langattomat radiot. Käyttöjärjestelmä on Debianiin perustuva Mendel Linux OS.

Tensor Processing Unit (TPU) on Googlen kehittämä ASIC-piiri, jota yritys käyttää muissakin tekoälyä hyödyntävissä ratkaisuissa. Se on kehitetty erityisesti hermostoverkkokoneiden oppimiseen Googlen omalla TensorFlow-ohjelmistolla.
Google aloitti ensimmäisten TPU-laitteiden hyödyntämisen sisäisesti jo viisi vuotta sitten, mutta toi pari vuotta sitten tekniikan ja pienemmän piirin myös kolmansien osapuolien käyttöön osana pilvipalveluitaan.
Tammikuussa 2019 Google toi Edge TPU -prosessorin uudella Coral-tuotemerkillä. Coral AI-tuotesarjaan kuuluu myös useita erilaisia moduuleita. Liitäntöinä on tarjolla USB, mini PCI-e tai M.2). Pienin tällä hetkellä saatavilla oleva Coral SoM -moduuli on kooltaan 40 x 48 millimetriä, mutta tarjolle on tulossa piakkoin sitäkin pienempi 10 x 15 millimetrin versio.
Edge TPU pystyy suorittamaan neljä biljoonaa operaatiota sekunnissa kahden watin tehonkulutuksella. Piiri tukee 8-bittin tarkkuudella toimivaa matematiikkaa. Piiri pystyy luomaan TensorFlow Lite -mallin mukaisia hermoverkkoja. Se on vain ensin koulutettava piirille TensorFlow-kvantisointitietoisella harjoitustekniikalla.
Uutuus sopii parhaiten valmiisiin malleihin perustuvien päättelyiden suorittamiseen. Esimerkiksi huipputekniset liikkuvan kuvan mallit, kuten MobileNet v2, energiatehokkaasti jopa satojen kuvien sekuntinopeudella.
AI-kiihdytystä Up squared -pikkukorttiin
Verkkomyynnissä oleva UP2-minikortti perustuu Intelin Apollo Lake -prosessoriin. Kortin kehityksessä ovat mukana Intelin lisäksi taiwailainen teollisuustietokoneiden valmistaja AAEON.

Kortilla oleva Intelin Gen 9 HD -grafiikkaprosessori tukee videokoodauksia 4K-tarkkuudella ja GPU-laskentaa. Kortilla voidaan tehdä koneoppimisen laskentaa keskusprosessorilla, grafiikkaprosessorilla tai valinnaisella lisäkiihdytinmoduulilla.
Liitäntöinä on useita USB 3.0 -portteja, kaksinkertainen Gigabit-Ethernet ja HDMI. Kortissa on 40-nastaisen I/O-liitin joka on yhteensopiva Raspberry Pi lisäkorttien kanssa. Kortti tukee useita käyttöjärjestelmiä, kuten Microsoft Windows 10 Pro/Home/ IoT, Windows IOT Core, Linux (ubilinux, Ubuntu, Yocto) ja Android Marshmallow
Sovelluskehittäjille on tarjolla UP Squared* AI Vision X Developer Kit -kokonaisuus, joka koostuu valmiiksi koteloidusta Intelin Atom x7 -prosessoria käyttävästä korttitietokoneesta sekä Intel Movidus-kiihdytinmoduulista (VPU).
Kehittäjäpaketti on suunniteltu hyödyntämään Intelin Distribution of OpenVINO -työkalupakkia konenäkösovellusten syvän oppimisen laitteistokiihdytykseen. Laitteisto sopii esimerkiksi ihmisten liikkeiden havaitsemiseen, kasvojen analysointiin, liikenteen seuraamiseen ja rekisterikilpien tunnistamiseen.

Linux-väen Ultra96-kortti
ARM-prosessoriympäristöön vetävä Linuxin Linaro-järjestö on kehittänyt ohjelmistojen lisäksi omia 96Boards-korttituotteita. Niiden valmistuksesta huolehtii kompoenttijakeluija Avnet Engineering Services -yksikkö.
Uusin Ultra96 V2 perustuu ARM:n kaksiytimiseen Cortex-R5F -moniprosessointijärjestelmään, jota avitetaan laskennassa Xilinsin FPGA-piirillä Zynq UltraScale + MPSoC.
Kortti tarjoaa käyttöön 64-bittisen prosessorin ja skaalautuvuuden reaaliaikaisen ohjauksen grafiikan, videon, äänisignaalien ja pakettien käsittelyyn. Tekoälysovelluksissa voidaan käyttää Caffe-, TensorFlow- ja Pyhoniin perustuvaa PYNQ-analysointikirjastoa.
Ultra96-V2-kortti voidaan käynnistää mukana tulevalta Delkin 16 gigatavun microSD-kortilta. Sen kanssa voidaan käyttää PetaLinux-työpöytäympäristön tai langattoman tukiaseman toimivan Web-palvelimen kautta.
Kortin suunnittelu perustuu Linaro 96Boards Consumer Edition (CE) -määritykseen ja sen kaikki komponentit on mitoitettu teollisuuskäytön lämpötila-alueelle, joten ratkaisua voidaan soveltaa myös ammattimaisessa käytössä.
More information on product is available thrugh magazine 1/2020 link bank
EXTRA1: Tarjolla AI-reunalaskentaa?
Reunalaskennasta ja AI-prosessoinnista puhutaan paljon yhdessä, koska ne liittyvät monissa sovelluksissa tiukasti yhteen. Kun halutaan toteuttaa hyvin nopeasti reaaliaikaisesti toimivia luotettavia järjestelmiä, ei voida läheskään aika tukeutua pilvikeskeiseen malliin.
Tekninen kehitys on viemässä koneoppimista ja tekoälyä yhä pienempiin laitteisiin. Tekoälyominaisuudet ovat jo tulleet älypuhelimiin ja tekoälyominaisuudet ovat vauhdilla tulossa sulautettuihin järjestelmiin ja jopa antureiden sisään.
Kun tällä hetkellä tarvitaan varmasti alle 200 millisekunnin vasteaikaa tai sovelluksen pitää toimia myös ilman verkkoyhteyttä, tekoälylaskenta on pakko tehdä itse laitteessa.
Tällaisia ominaisuuksia vaikkapa luonnollisen kielen käännös lennossa sekä robottiautojen ADAS-järjestelmien tekoäly. Esimerkiksi itse ajavan auton anturit tuottavat niin paljon dataa, että sitä kaikkea ei voi mitenkään realistisesti siirtää reaaliaikaisesti muualle prosessoitavaksi, vaan prosessointi pitää tapahtua itse autossa olevalla tekniikalla.
Paikallista käsittelyä puoltaa myös se, että kuluttajat ovat nykyisin paljon kriittisempiä sille, kuinka paljon ja millaista dataa heidän käyttäytymisestään syötetään pilveen.
EXTRA2: Korttipohjaisia ratkaisuja kuvantunnistukseen
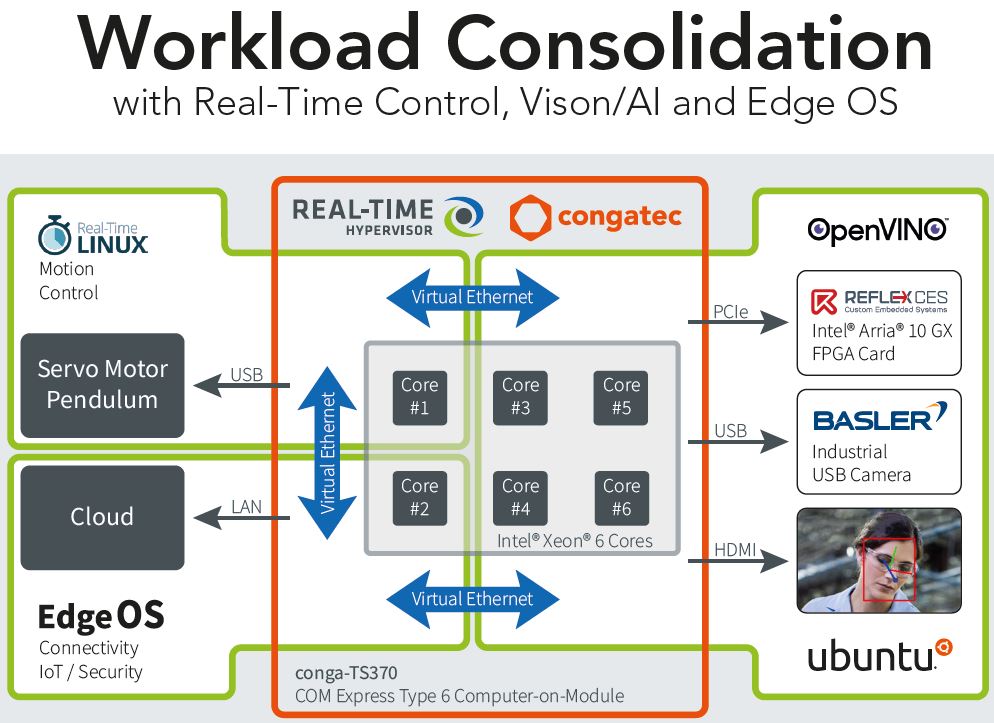
Cognatec, Basler ja Real-Time Systems ovat kehittäneet yhteistyössä joustavan korttipohjaisen alustan konenäkö- ja AI-sovelluksiin. Tehokkaat suoritinkortit ovat tarpeen teollisuuden kuvankäsittelyratkaisuissa.
Jutussa esiteltyjen AI-laskentaan sopivien korttien lisäksi tarjolla kokonaisratkaisuja. Esimerkiksi Congatec esitteli Japanissa vuosi sitten tytäryhtiö Real-Time Systemsin ja kameravalmistaja Baslerin kanssa useita valmiita AI-pohjaisia alustoja kuvantunnistussovelluksiin.
Niistä tehokkain tunnistusratkaisu perustui Xeon E2 -pohjaiseen COM Express Type 6 -moduuliin, jota oli terästetty AI-algoritmia pyörittävällä Refexcesin Intelin Arria 10 FPGA-pohjaisella lisäkortilla. Objektintunnistus tehtiin OpenVino-ohjelmistolla Linux-käyttöjärjestelmässä.
Samassa tilaisuudessa esiteltiin myös keveämpi kasvojentunnistusdemo, joka rakentui Baslerin kamera-alustalla ja Congatecin Pico-ITX-kortilla.
Toinen ratkaisu perustui Basler Embedded Vision -tuotesarjaan, joka rakentui NXP i.MX 8 QuadMax SoC -pohjaisesta Congatecin SMARC 2.0 -moduulista, liitäntäkortista ja Baslerin dart BCON MIPI 13 MP -kameramoduulista.
Artikkelin kirjoittaja Tomi Engdahl toimii Netcontrol Oy:ssä tuotekehitysinsinöörinä. Hänellä on pitkä kokemus sulautettujen ja IoT-ratkaisujen tietoturvaratkaisuista.
 Kokosimme Uusiteknologia 1/2020-lehden linkkiosioon tietoa tekoälytekniikoista ja suorat kehittäjälinkit artikkelissa esiteltyihin korttituotteisiin ja niiden valmistajiin. Mukana on linkit aiempiin Uusiteknologia-lehden artikkeleihin (LINKKI).
Kokosimme Uusiteknologia 1/2020-lehden linkkiosioon tietoa tekoälytekniikoista ja suorat kehittäjälinkit artikkelissa esiteltyihin korttituotteisiin ja niiden valmistajiin. Mukana on linkit aiempiin Uusiteknologia-lehden artikkeleihin (LINKKI).
EXTRA3: ENGLISH SUMMARY – Artficial intelligence is also coming into embedded systems
Artificial intelligence will be seen even more more often an important part of the future of the Internet of Things and, for example, robots and development of autonomous vehicles. The need to process data more and more where data is being created, is taking machine learning and artificial intelligence to ever smaller devices. We gathered here article on basic information about artificial intelligence. In addition, we present seven processor cards with can be used to implement the first practical artificial intelligence controls. You can find more about New Technology 1/2020 via the link bank (LINK).
ALOITUSKUVA: NVIDIA:n Jetson Nano-kortin prosessori pystyy tarjoamaan jopa 472 GFLOPS laskentakapasiteetin AI-sovelluksiin. Se on tarjolla korttitietokoneena tai sulautettavana moduulina. The NVIDIA Jetson Nano card has powerful processor is capable of providing up to 472 GFLOPS of computing capacity for AI applications. Nano is available as both a card computer and a plug-in module.